Tutorials
Geoprocessing
Goals
This notebook will walk through some common geoprocessing tasks using geopandas. These operations include:
- reprojecting data
- using a mask to clip data
- performing a spatial join
- performing an attribute join
- dissolving data
- unioning data
- writing functions to calculate new attributes
Together, these operations form the basis of many geospatial analyses. These tools are used to explore our datasets and the relationships between them, a common first step in any geospatial analysis.
Import libraries
import matplotlib.pyplot as plt
from shapely.geometry import Polygon
import geopandas as gpd
from lonboard._map import Map
from lonboard.layer import PolygonLayer
from lonboard.colormap import apply_categorical_cmap# global map plot settings
plt.rcParams["figure.figsize"] = (10, 10)
# We are doing a lot of plotting, and at the scale we're working, we don't need to see coordinates on the axes.
# We can turn off the axes and ticks by default to keep the plots clean.
# Instead of running this cell, you could add `set_axis_off()` to each plot you create.
def set_axis_off():
"""
Set the default matplotlib settings to turn off axes and ticks.
This function modifies the global matplotlib configuration to hide axes and ticks
for all plots created after this function is called.
"""
# set axis off by default
plt.rcParams["axes.axisbelow"] = False
plt.rcParams["axes.axisbelow"] = False
plt.rcParams["axes.spines.left"] = False
plt.rcParams["axes.spines.right"] = False
plt.rcParams["axes.spines.top"] = False
plt.rcParams["axes.spines.bottom"] = False
# set tick params off by default
plt.rcParams["xtick.bottom"] = False
plt.rcParams["xtick.top"] = False
plt.rcParams["xtick.labelbottom"] = False
plt.rcParams["xtick.labeltop"] = False
plt.rcParams["ytick.left"] = False
plt.rcParams["ytick.right"] = False
plt.rcParams["ytick.labelleft"] = False
plt.rcParams["ytick.labelright"] = FalseNow we can run the function to set the default settings for this notebook.
set_axis_off()Import datasets
As you may have noticed in the previous notebook, Pluto is a huge dataset that takes a long time to load. In geopandas, you can use the where=... argument to load only a subset of the data. This is useful when you want to work with a smaller area or a specific set of features. In this case, we will focus only on tax lots within Brooklyn’s community district 7 (where="CD = 307"). This will significantly speed up the loading process (and takes out the additional step of filtering the data later).
cb_307 = gpd.read_file(
"../Data/nyc_mappluto_24v1_1_shp/mappluto_ogr.fgb", where="CD = 307"
)To get to know CD 307 a bit better, let’s check the distribution of land use types in this community district.
cb_307.LandUse.value_counts()LandUse
One & Two Family Buildings 6299
Multi-Family Walk-Up Buildings 3731
Mixed Residential & Commercial Buildings 1635
Industrial & Manufacturing 603
Commercial & Office Buildings 247
Vacant Land 165
Public Facilities & Institutions 164
Transportation & Utility 137
Parking Facilities 123
Multi-Family Elevator Buildings 90
Unknown 49
Open Space & Outdoor Recreation 41
Name: count, dtype: int64cb_307.plot()<Axes: >
With this trick, we are able to load only a subset of lots that we are interested in. Next we will load in building foorprints, but that dataset does not have the CD attribute to be able to filter by. Instead, we will use a geometric filter based on the bounds of our tax lot geodataframe.
We can get the “total bounds” of our dataset using the total_bounds property of the GeoDataFrame.
The “total bounds” is an array of the minimum and maximum x and y coordinates of the geometries in the GeoDataFrame- it is a minimum bounding rectagle for the entire dataset.
# get maximum bounding geometry for all tax lots
bounds = cb_307.total_boundsLet’s visually inspect the bounds of our tax lots.
boundsarray([975222.90192556, 170552.42205763, 992130.25818682, 183853.30228138])As an array, this isn’t much use to us yet- we need to convert it to a polygon object to be able to use it as a filter. Note that we are also passing the crs argument to ensure that the polygon is in the same coordinate reference system as our tax lots (and is aware of that fact).
bounds_poly = gpd.GeoSeries(
Polygon(
[
[bounds[0], bounds[1]],
[bounds[0], bounds[3]],
[bounds[2], bounds[3]],
[bounds[2], bounds[1]],
[bounds[0], bounds[1]],
]
),
crs=cb_307.crs,
)Now we can see that the bounds are a polygon that covers the entire area of interest.
bounds_poly.explore()<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<script src="https://cdn.jsdelivr.net/npm/leaflet@1.9.3/dist/leaflet.js"></script>
<script src="https://code.jquery.com/jquery-3.7.1.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/js/bootstrap.bundle.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/Leaflet.awesome-markers/2.0.2/leaflet.awesome-markers.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/leaflet@1.9.3/dist/leaflet.css"/>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.2/dist/css/bootstrap.min.css"/>
<link rel="stylesheet" href="https://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap-glyphicons.css"/>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@fortawesome/fontawesome-free@6.2.0/css/all.min.css"/>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/Leaflet.awesome-markers/2.0.2/leaflet.awesome-markers.css"/>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/gh/python-visualization/folium/folium/templates/leaflet.awesome.rotate.min.css"/>
<meta name="viewport" content="width=device-width,
initial-scale=1.0, maximum-scale=1.0, user-scalable=no" />
<style>
#map_bfb027c18c01349af48fc88fb3ae36bf {
position: relative;
width: 100.0%;
height: 100.0%;
left: 0.0%;
top: 0.0%;
}
.leaflet-container { font-size: 1rem; }
</style>
<style>html, body {
width: 100%;
height: 100%;
margin: 0;
padding: 0;
}
</style>
<style>#map {
position:absolute;
top:0;
bottom:0;
right:0;
left:0;
}
</style>
<script>
L_NO_TOUCH = false;
L_DISABLE_3D = false;
</script>
<style>
.foliumtooltip {
}
.foliumtooltip table{
margin: auto;
}
.foliumtooltip tr{
text-align: left;
}
.foliumtooltip th{
padding: 2px; padding-right: 8px;
}
</style>
</head> <body>
<div class="folium-map" id="map_bfb027c18c01349af48fc88fb3ae36bf" ></div>
</body> <script>
var map_bfb027c18c01349af48fc88fb3ae36bf = L.map(
"map_bfb027c18c01349af48fc88fb3ae36bf",
{
center: [40.653053489029915, -74.00206712173816],
crs: L.CRS.EPSG3857,
...{“zoom”: 10, “zoomControl”: true, “preferCanvas”: false, }
}
);
L.control.scale().addTo(map_bfb027c18c01349af48fc88fb3ae36bf);
var tile_layer_c285ae4960db019eb433b8de9c6b8466 = L.tileLayer(
"https://tile.openstreetmap.org/{z}/{x}/{y}.png",
{“minZoom”: 0, “maxZoom”: 19, “maxNativeZoom”: 19, “noWrap”: false, “attribution”: “\u0026copy; \u003ca href="https://www.openstreetmap.org/copyright\"\u003eOpenStreetMap\u003c/a\u003e contributors”, “subdomains”: “abc”, “detectRetina”: false, “tms”: false, “opacity”: 1, }
);
tile_layer_c285ae4960db019eb433b8de9c6b8466.addTo(map_bfb027c18c01349af48fc88fb3ae36bf);
map_bfb027c18c01349af48fc88fb3ae36bf.fitBounds(
[[40.63479893512957, -74.03254179117269], [40.67130804293027, -73.97159245230364]],
{}
);
function geo_json_b1fb4e46a54419c826877a95c503f03b_styler(feature) {
switch(feature.id) {
default:
return {"fillOpacity": 0.5, "weight": 2};
}
}
function geo_json_b1fb4e46a54419c826877a95c503f03b_highlighter(feature) {
switch(feature.id) {
default:
return {"fillOpacity": 0.75};
}
}
function geo_json_b1fb4e46a54419c826877a95c503f03b_pointToLayer(feature, latlng) {
var opts = {“stroke”: true, “color”: “#3388ff”, “weight”: 3, “opacity”: 1.0, “lineCap”: “round”, “lineJoin”: “round”, “dashArray”: null, “dashOffset”: null, “fill”: true, “fillColor”: “#3388ff”, “fillOpacity”: 0.2, “fillRule”: “evenodd”, “bubblingMouseEvents”: true, “radius”: 2, };
let style = geo_json_b1fb4e46a54419c826877a95c503f03b_styler(feature)
Object.assign(opts, style)
return new L.CircleMarker(latlng, opts)
}
function geo_json_b1fb4e46a54419c826877a95c503f03b_onEachFeature(feature, layer) {
layer.on({
mouseout: function(e) {
if(typeof e.target.setStyle === "function"){
geo_json_b1fb4e46a54419c826877a95c503f03b.resetStyle(e.target);
}
},
mouseover: function(e) {
if(typeof e.target.setStyle === "function"){
const highlightStyle = geo_json_b1fb4e46a54419c826877a95c503f03b_highlighter(e.target.feature)
e.target.setStyle(highlightStyle);
}
},
});
};
var geo_json_b1fb4e46a54419c826877a95c503f03b = L.geoJson(null, {
onEachFeature: geo_json_b1fb4e46a54419c826877a95c503f03b_onEachFeature,
style: geo_json_b1fb4e46a54419c826877a95c503f03b_styler,
pointToLayer: geo_json_b1fb4e46a54419c826877a95c503f03b_pointToLayer,
...{} });
function geo_json_b1fb4e46a54419c826877a95c503f03b_add (data) {
geo_json_b1fb4e46a54419c826877a95c503f03b
.addData(data);
}
geo_json_b1fb4e46a54419c826877a95c503f03b_add({"bbox": [-74.03254179117269, 40.63479893512957, -73.97159245230364, 40.67130804293027], "features": [{"bbox": [-74.03254179117269, 40.63479893512957, -73.97159245230364, 40.67130804293027], "geometry": {"coordinates": [[[-74.03252398842326, 40.63479893512957], [-74.03254179117269, 40.6713069478188], [-73.97159245230364, 40.67130804293027], [-73.97160799331864, 40.634800029646485], [-74.03252398842326, 40.63479893512957]]], "type": "Polygon"}, "id": "0", "properties": {}, "type": "Feature"}], "type": "FeatureCollection"});
geo_json_b1fb4e46a54419c826877a95c503f03b.bindTooltip(
function(layer){
let div = L.DomUtil.create('div');
return div
}
,{“sticky”: true, “className”: “foliumtooltip”, });
geo_json_b1fb4e46a54419c826877a95c503f03b.addTo(map_bfb027c18c01349af48fc88fb3ae36bf);
</script> </html>” style=“position:absolute;width:100%;height:100%;left:0;top:0;border:none !important;” allowfullscreen webkitallowfullscreen mozallowfullscreen>
If we plot both datasets together and zoom in, you can see that the bounding polygon exactly matches the extent of the tax lots.
ax = cb_307.plot()
bounds_poly.boundary.plot(ax=ax, color="red")<Axes: >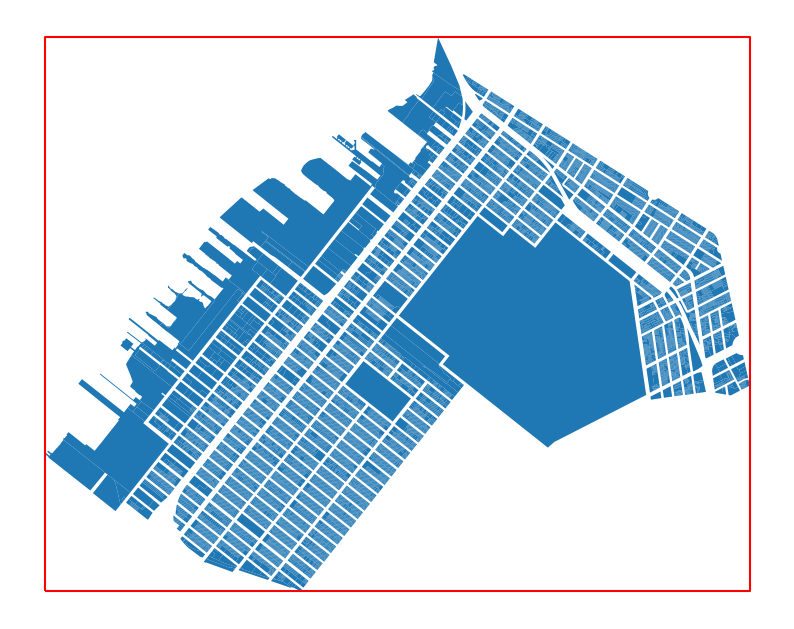
Aligning dataset projections
We saw in the previous exercise that the buildings geojson file has a CRS of EPSG:4326, which is WGS84. Unlike desktop GIS software, GeoPandas does not reproject on-the-fly; as such, we need to explicitly align projections between our datasets to be able to work with them together.
You can check a dataset’s CRS (Coordinate Reference System) with the .crs attribute. If this returns None, the dataset does not have a CRS defined and you can set it with the .set_crs([crs-here]) method or [dataset].crs = [crs-here].
cb_307.crs<Projected CRS: EPSG:2263>
Name: NAD83 / New York Long Island (ftUS)
Axis Info [cartesian]:
- X[east]: Easting (US survey foot)
- Y[north]: Northing (US survey foot)
Area of Use:
- name: United States (USA) - New York - counties of Bronx; Kings; Nassau; New York; Queens; Richmond; Suffolk.
- bounds: (-74.26, 40.47, -71.8, 41.3)
Coordinate Operation:
- name: SPCS83 New York Long Island zone (US survey foot)
- method: Lambert Conic Conformal (2SP)
Datum: North American Datum 1983
- Ellipsoid: GRS 1980
- Prime Meridian: Greenwichbounds_poly.crs<Projected CRS: EPSG:2263>
Name: NAD83 / New York Long Island (ftUS)
Axis Info [cartesian]:
- X[east]: Easting (US survey foot)
- Y[north]: Northing (US survey foot)
Area of Use:
- name: United States (USA) - New York - counties of Bronx; Kings; Nassau; New York; Queens; Richmond; Suffolk.
- bounds: (-74.26, 40.47, -71.8, 41.3)
Coordinate Operation:
- name: SPCS83 New York Long Island zone (US survey foot)
- method: Lambert Conic Conformal (2SP)
Datum: North American Datum 1983
- Ellipsoid: GRS 1980
- Prime Meridian: GreenwichTo be able to use our bounds polygon to filter the building footprints dataset, we’ll need to create a copy of the bounds that are in the right coordinate system. we can create a copy and use the to_crs() method to convert into the proper system
bounds_poly_wgs84 = bounds_poly.to_crs("EPSG:4326")We can confirm that the CRS has changed by checking the CRS attribute again.
bounds_poly_wgs84.crs<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- name: World.
- bounds: (-180.0, -90.0, 180.0, 90.0)
Datum: World Geodetic System 1984 ensemble
- Ellipsoid: WGS 84
- Prime Meridian: GreenwichSimilar to the attribute filter we used previously to only load tax lots in CD 307, we can use a spatial filter to only load building footprints that intersect with our bounds polygon using the mask=... argument in our input statement.
cb_307_bldgs = gpd.read_file(
"../Data/bldg_footprints/Building Footprints.geojson",
mask=bounds_poly_wgs84[0],
)Now let’s visually inpect the buildings in the area of interest.
cb_307_bldgs.plot()<Axes: >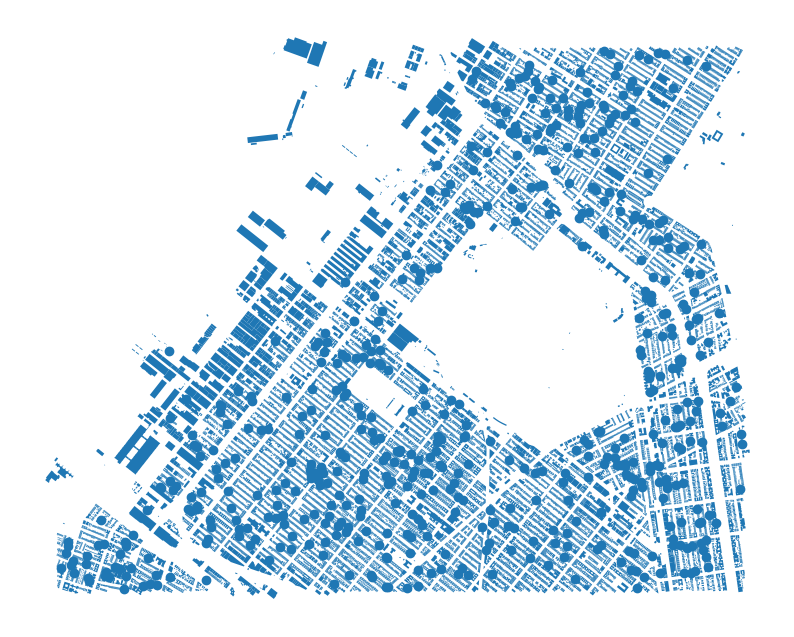
So, we are able to successfully read in the building footprints within thd study area and plot them- however, we see that there are also point representations of buildings along with the expected polygon shapes. Let’s exclude point type features to be able to work specifically with polygons:
cb_307_bldgs = cb_307_bldgs[cb_307_bldgs.geometry.type != "Point"]cb_307_bldgs.plot()<Axes: >
cb_307_bldgs = cb_307_bldgs.to_crs(cb_307.crs)cb_307_bldgs.plot()<Axes: >
Combine building footprints and tax lot data
To combine our building footprints with tax lots, we will compare the spatial relations between the two geometries. There are a few quirks to keep in mind:
- in some cases, buildings can cross between tax lots, leaving open the possibility that there are multiple matching tax lots for a single building footprint.
- in other cases, a building footprint may not intersect with any tax lot, such as when a building is on a sidewalk or in a park.
Because of these quirks, we will use a representation of the building footprints that is a representative point of the polygon, which is a single point representation of the building footprint. This will allow us to match each building footprint to a single tax lot.
It’s worth mentioning that the buildings do have join attributes that we could use to join the two datasets (mpluto_bbl and base_bbl), but for the purposes of this exercise, we will focus on the spatial join.
Note:
Therepresentative_point()method is a way to get a point that is guaranteed to be within the polygon, even if the polygon is complex or has holes. This is useful for matching geometries that may not overlap perfectly. This is a related concept to thecentroidmethod, which returns the center point of the polygon, but the representative point is guaranteed to be within the polygon.
To illustrate this point, we’ll take a random building footprint using the sample() method. We’ll look at it’s simplified geometry using the boundary property, along with the representative point of the polygon.
ss = cb_307_bldgs.sample()
ax = ss.boundary.plot()
ss.representative_point().plot(ax=ax)<Axes: >
Okay, now that we understand the concept of representative points, let’s generate one for each building footprint in our dataset. We’ll then set this column as the geometry of the GeoDataFrame so that we can use it for spatial operations (while still keeping the original geometry for reference).
cb_307_bldgs["rep_pt"] = cb_307_bldgs.representative_point()
cb_307_bldgs.set_geometry("rep_pt", inplace=True)Let’s take a look- we can see two geometry columns now, one for the original building footprint and one for the representative point.
cb_307_bldgs.head()| name | base_bbl | shape_area | heightroof | mpluto_bbl | cnstrct_yr | globalid | lststatype | feat_code | groundelev | geomsource | bin | lstmoddate | doitt_id | shape_len | geometry | rep_pt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 3008130054 | 0.0 | 31.05 | 3008130054 | 1901 | {C2B6150A-AA05-4865-B836-9DFA5C153E9C} | Constructed | 2100 | 48 | Photogramm | 3014166 | 2017-08-22 | 392052 | 0.0 | MULTIPOLYGON (((979424.884 174653.762, 979393.... | POINT (979402.531 174638.9) |
| 1 | NaN | 3010120038 | 0.0 | 42.44 | 3010120038 | 1921 | {65E24ABD-485B-4B01-B70E-5ACA0E221B53} | Constructed | 2100 | 115 | Photogramm | 3022371 | 2017-08-22 | 743038 | 0.0 | MULTIPOLYGON (((989250.122 182249.393, 989226.... | POINT (989230.47 182235.219) |
| 2 | NaN | 3053130127 | 0.0 | 26.38239517 | 3053130127 | 1940 | {454D03AE-5F41-4886-A5C5-74DD122005EF} | Constructed | 2100 | 57 | Photogramm | 3123939 | 2017-08-22 | 785686 | 0.0 | MULTIPOLYGON (((989342.25 173309.206, 989328.4... | POINT (989345.27 173325.92) |
| 3 | NaN | 3058710090 | 0.0 | 24.71 | 3058710090 | 1920 | {F02017F9-C56E-4793-96D1-03741F2569AC} | Constructed | 2100 | 73 | Photogramm | 3145644 | 2017-08-22 | 560761 | 0.0 | MULTIPOLYGON (((976372.261 170905.43, 976404.2... | POINT (976382.124 170892.831) |
| 4 | NaN | 3058850095 | 0.0 | 26.79 | 3058850095 | 1925 | {D97E7A81-466F-47F7-9159-D52052EC7129} | Constructed | 2100 | 68 | Photogramm | 3146300 | 2017-08-22 | 541427 | 0.0 | MULTIPOLYGON (((975991.817 170852.23, 975985.9... | POINT (975969.477 170848.875) |
Of course, there are plenty of cases where there are multiple buildings on a single tax lot. We can compare the number of unique tax lot ids with the number of buildings / building IDs to get a sense of this relationshp:
print(
f"There are {cb_307_bldgs.base_bbl.nunique()} unique base BBLs in Community Board 307, \nalong with {cb_307_bldgs.shape[0]} total buildings and {cb_307_bldgs.globalid.nunique()} unique building IDs."
)There are 26357 unique base BBLs in Community Board 307,
along with 30113 total buildings and 30113 unique building IDs.Perform spatial join
Now we will use the spatial join operation to join the building footprints to the tax lots based on the relationship between the representative points and lot polygons. The spatial join is a fundamental operation in GIS that allows us to combine attributes from two different datasets based on their spatial relationship. Read more about geopandas’ implementation of spatial joins in the documentation, and note that some of the directives have changed between recent versions.
Here we take a subset of attributes of the buildings layer, denoted in the double brackets [[...]] and use the sjoin() method to join to the tax lots layer.
We are performing an inner join, matching overlapping features between the two datasets, vs. an outer, right, or left join. We are also using the spatial predicate within to specify what kind of spatial relationship we want to use as the basis of the join.
## spatial join buildings to tax lots based on building representative point
bldgs_w_lot = cb_307_bldgs[["globalid", "mpluto_bbl", "rep_pt"]].sjoin(
cb_307, how="inner", predicate="within"
)bldgs_w_lot.head()| globalid | mpluto_bbl | rep_pt | index_right | Borough | Block | Lot | CD | BCT2020 | BCTCB2020 | ... | PFIRM15_FL | Version | DCPEdited | Latitude | Longitude | Notes | Shape_Leng | Shape_Area | NumFloorsCluster | color | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {C2B6150A-AA05-4865-B836-9DFA5C153E9C} | 3008130054 | POINT (979402.531 174638.9) | 6880 | BK | 813 | 54 | 307 | 3002000 | 30020002002 | ... | NaN | 24v1.1 | NaN | 40.646041 | -74.017448 | None | 0.0 | 1756.742220 | 0 | #ff0000 |
| 6 | {6290F624-6A8D-482F-8BD9-57C27337D89F} | 3008370001 | POINT (978532.245 174359.877) | 7179 | BK | 837 | 1 | 307 | 3002200 | 30022002000 | ... | NaN | 24v1.1 | NaN | 40.645239 | -74.020500 | None | 0.0 | 19141.495406 | 2 | #800000 |
| 7 | {F68D5818-C246-4828-A454-10D28962217D} | 3007890064 | POINT (979672.912 175444.4) | 7747 | BK | 789 | 64 | 307 | 3002000 | 30020001003 | ... | NaN | 24v1.1 | NaN | 40.648210 | -74.016515 | None | 0.0 | 6152.697688 | 0 | #ffff00 |
| 9 | {441DAB8C-3423-4722-ABDE-4BFE5A472C2B} | 3052800064 | POINT (989860.229 175412.619) | 12324 | BK | 5280 | 64 | 307 | 3050001 | 30500011001 | ... | NaN | 24v1.1 | NaN | 40.648203 | -73.979830 | None | 0.0 | 2138.490866 | 0 | #ff00ff |
| 11 | {B8BC6B19-B2E4-4842-8B03-5C28CC13A572} | 3011150070 | POINT (990278.753 178961.422) | 1061 | BK | 1115 | 70 | 307 | 3017100 | 30171002000 | ... | NaN | 24v1.1 | NaN | 40.657928 | -73.978234 | None | 0.0 | 2055.187662 | 0 | #ff0000 |
5 rows × 100 columns
Let’s try a different approach- we can use a similar function, sjoin_nearest() to join features to the nearest feature in the target dataset. In this example, we are performing a left join, which means we are keeping all features in the input dataset, but we need to keep in mind that there may be cases where multiple input features are closest to a target (tax lot) feature. There’s an optional argument for the function, exclusive which defaults to False, which would allow us to prevent duplicate matches.
We will pass in an additional optional argument, distance_col, which will calculate and record the distance from our input features from the matching target feature. This is important as we explore the spatial relationship between our datasets.
bldgs_w_lot_nearest = cb_307_bldgs[["globalid", "mpluto_bbl", "rep_pt"]].sjoin_nearest(
cb_307, how="left", distance_col="distance"
)We can plot the distance field to visualize how far each input feature is from a target feature. What do you notice?
bldgs_w_lot_nearest.plot("distance", legend=True)<Axes: >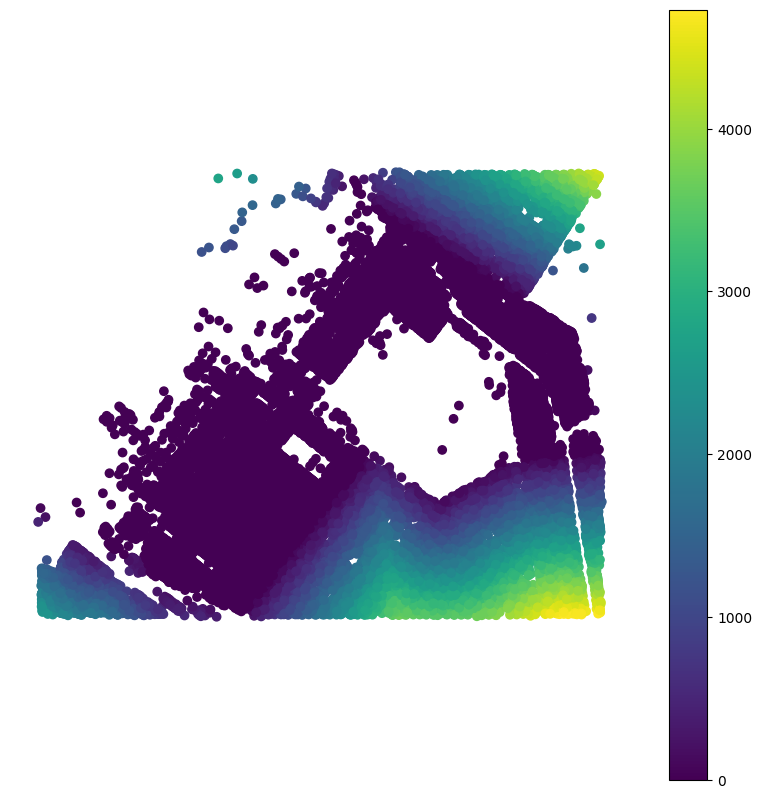
Now let’s visualize our building points on top of our tax lots
ax = cb_307.plot(color="#ababab")
bldgs_w_lot.plot(ax=ax, color="red", alpha=0.5)<Axes: >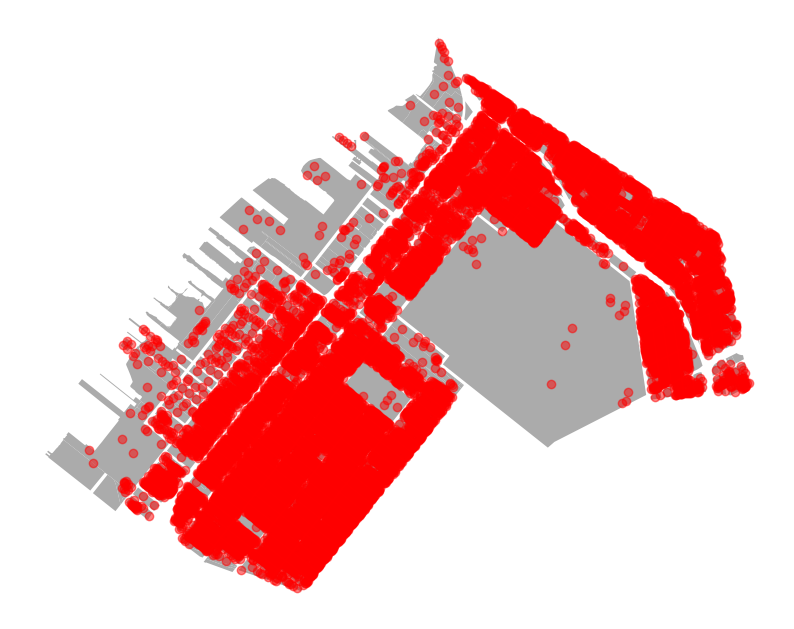
Merge back with footprints
Now that we’ve associated each tax lot with every building’s representative point, we can merge back with the input footprint geometry to be able to represent the data using footprints.
In the below example, we are chaining a few different operations together:
- using the
drop()function to get rid of therep_ptcolumn, which we no longer need - using the
merge()function to merge the data we do want to keep with our previous building footprints dataset, making sure to only keep the building footprints with matches (based on theleftdirective)
# now, join back to original building footprints
bldgs_w_lot = bldgs_w_lot.drop(columns=["rep_pt"]).merge(
cb_307_bldgs, on="globalid", how="left"
)We need to cast our new dataset explicitly as a geodataframe for geopandas to be able to recognize that geometry is a special column.
bldgs_w_lot_gdf = gpd.GeoDataFrame(bldgs_w_lot, geometry="geometry")bldgs_w_lot_gdf.plot()<Axes: >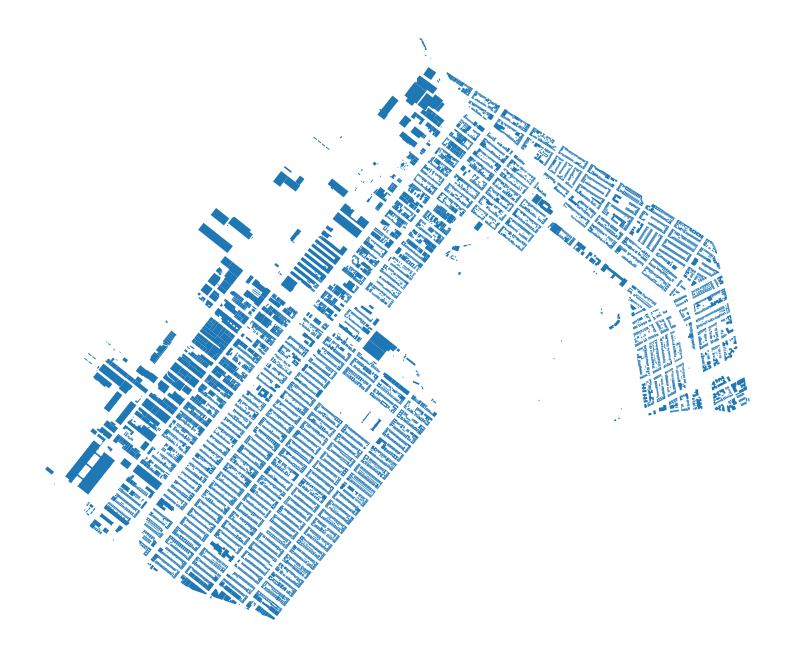
… and we’ll borrow the colormap we created in the first notebook here to be able to produce a consistent representation of land uses on a per-lot and building basis
cmap = {
"One & Two Family Buildings": "#ffff00",
"Multi-Family Walk-Up Buildings": "#fffb00",
"Multi-Family Elevator Buildings": "#ffc800",
"Mixed Residential & Commercial Buildings": "#ff4000",
"Commercial & Office Buildings": "#ff0000",
"Industrial & Manufacturing": "#7700ff",
"Transportation & Utility": "#808080",
"Public Facilities & Institutions": "#001580",
"Open Space & Outdoor Recreation": "#219F21",
"Parking Facilities": "#A6A6AB",
"Vacant Land": "#222222",
"Unknown": "#000000",
}Similarly, we will convert the hex code-based cmap to the RGB-type representation that lonboard needs for visualizing
cmap_rgb = {k: list(int(v[i : i + 2], 16) for i in (1, 3, 5)) for k, v in cmap.items()}bldgs_w_lot_gdf["LandUse"].fillna("Unknown", inplace=True)/var/folders/g5/b592wl6x12s0tx4jfw9f7_j40000gn/T/ipykernel_27210/1624109216.py:1: ChainedAssignmentError: A value is being set on a copy of a DataFrame or Series through chained assignment using an inplace method.
Such inplace method never works to update the original DataFrame or Series, because the intermediate object on which we are setting values always behaves as a copy (due to Copy-on-Write).
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' instead, to perform the operation inplace on the original object, or try to avoid an inplace operation using 'df[col] = df[col].method(value)'.
See the documentation for a more detailed explanation: https://pandas.pydata.org/pandas-docs/stable/user_guide/copy_on_write.html
bldgs_w_lot_gdf["LandUse"].fillna("Unknown", inplace=True)0 One & Two Family Buildings
1 Public Facilities & Institutions
2 Industrial & Manufacturing
3 Mixed Residential & Commercial Buildings
4 One & Two Family Buildings
...
14310 One & Two Family Buildings
14311 One & Two Family Buildings
14312 One & Two Family Buildings
14313 One & Two Family Buildings
14314 Mixed Residential & Commercial Buildings
Name: LandUse, Length: 14315, dtype: strLet’s visually inspect the relationships between land use and color columns just to make sure things are mapped properly.
bldgs_w_lot_gdf[["color", "LandUse"]].sample(10)| color | LandUse | |
|---|---|---|
| 8853 | #ff00ff | Mixed Residential & Commercial Buildings |
| 4886 | #ff0000 | One & Two Family Buildings |
| 4299 | #00ff00 | Multi-Family Walk-Up Buildings |
| 3643 | #00ff00 | Multi-Family Walk-Up Buildings |
| 13379 | #ff0000 | One & Two Family Buildings |
| 339 | #ffff00 | Industrial & Manufacturing |
| 13687 | #ff0000 | One & Two Family Buildings |
| 19 | #800000 | Public Facilities & Institutions |
| 5631 | #ff0000 | One & Two Family Buildings |
| 7243 | #ff0000 | One & Two Family Buildings |
Now let’s use lonboard to plot the output in 3D. we should be able to see each building shaded in the color that represents a land use based off it’s spatial relationship with tax lots from the previous steps. Because each building footprint has an estimated height field (heightroof), we can use that as the extrude height for each feature.
# make a lonboard plot with color based on land use and height based on number of floors
heights = bldgs_w_lot_gdf["heightroof"].astype(float).to_numpy()
bldgs_layer = PolygonLayer.from_geopandas(
bldgs_w_lot_gdf[["geometry", "LandUse"]].to_crs("EPSG:4326"),
get_fill_color=apply_categorical_cmap(bldgs_w_lot_gdf["LandUse"], cmap=cmap_rgb),
extruded=True,
get_elevation=heights,
)
m = Map(
[bldgs_layer],
view_state={
"pitch": 45,
"zoom": 14,
"latitude": 40.6459406,
"longitude": -74.0151512,
},
)
mAcross the above steps, we’ve witnessed how the spatial relationships between different datasets can be messy- items can overlap with multiple features, or not overlap with any features! At every step, we need to investigate how and to what degree our data matches. Thankfully, as we saw above, these datasets do share an attribute that can be used to connect: the bbl identifier, which stands for borough block lot.
We will use this shared attribute as the basis for a join in the next steps.
Performing attribute joins
Remember that we brought in the building footprints layer based on a mask, and that the building footprints’ extent exceeds that of the community district we are interested in. We can confirm this by looking at the number of unique mpluto_bbl entries vs the number of records in our cb_307 dataset.
cb_307_bldgs.mpluto_bbl.nunique(), cb_307.shape[0](26320, 13284)Before we merge, together, we need to confirm that the BBLs are encoded as the same data type- as we see below, the building footprints dataset encodes the BBLs as O or objects (i.e. as strings) and the tax lot dataset encodes them as float64 numbers. We’ll need to convert one or the other to be able to join them together
cb_307_bldgs.mpluto_bbl.dtype, cb_307.BBL.dtype(<StringDtype(na_value=nan)>, dtype('float64'))We can convert the building mpluto_bbl field as floats to match the tax lot dataset. We could just as easily go in the opposite direction and convert the tax lot dataset to objects instead (e.g. ...astype(str))
cb_307_bldgs["mpluto_bbl"] = cb_307_bldgs["mpluto_bbl"].astype(float)Now we can merge the datasets together- in cases where the join field is not the same, you have to specify left_on=... and right_on=... instead of just on=.... Since we are only interested in cases where the records overlap (i.e. in CB 307), we will do an inner join. In this particular case, that’s the same as doing a right join.
We will also use the suffixes attribute to properly name fields that exist in both datasets to not get confused later. (The default behavior is to append _x and _y to matching columns).
bldgs_w_lot_attrib = cb_307_bldgs.merge(
cb_307,
left_on="mpluto_bbl",
right_on="BBL",
how="inner",
suffixes=["_bldg", "_lot"],
)bldgs_w_lot_attrib.head()| name | base_bbl | shape_area | heightroof | mpluto_bbl | cnstrct_yr | globalid | lststatype | feat_code | groundelev | ... | Version | DCPEdited | Latitude | Longitude | Notes | Shape_Leng | Shape_Area | NumFloorsCluster | color | geometry_lot | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 3008130054 | 0.0 | 31.05 | 3.008130e+09 | 1901 | {C2B6150A-AA05-4865-B836-9DFA5C153E9C} | Constructed | 2100 | 48 | ... | 24v1.1 | NaN | 40.646041 | -74.017448 | None | 0.0 | 1756.742220 | 0 | #ff0000 | MULTIPOLYGON (((979369.047 174612.71, 979433.9... |
| 1 | NaN | 3008370001 | 0.0 | 64.47 | 3.008370e+09 | 1994 | {6290F624-6A8D-482F-8BD9-57C27337D89F} | Constructed | 2100 | 36 | ... | 24v1.1 | NaN | 40.645239 | -74.020500 | None | 0.0 | 19141.495406 | 2 | #800000 | MULTIPOLYGON (((978622.171 174415.821, 978651.... |
| 2 | NaN | 3007890064 | 0.0 | 25.85 | 3.007890e+09 | 1931 | {F68D5818-C246-4828-A454-10D28962217D} | Constructed | 2100 | 32 | ... | 24v1.1 | NaN | 40.648210 | -74.016515 | None | 0.0 | 6152.697688 | 0 | #ffff00 | MULTIPOLYGON (((979658.965 175378.734, 979612.... |
| 3 | NaN | 3052800064 | 0.0 | 23.66 | 3.052800e+09 | 1931 | {441DAB8C-3423-4722-ABDE-4BFE5A472C2B} | Constructed | 2100 | 62 | ... | 24v1.1 | NaN | 40.648203 | -73.979830 | None | 0.0 | 2138.490866 | 0 | #ff00ff | MULTIPOLYGON (((989842.608 175466.797, 989842.... |
| 4 | NaN | 3011150070 | 0.0 | 30.11 | 3.011150e+09 | 1901 | {B8BC6B19-B2E4-4842-8B03-5C28CC13A572} | Constructed | 2100 | 147 | ... | 24v1.1 | NaN | 40.657928 | -73.978234 | None | 0.0 | 2055.187662 | 0 | #ff0000 | MULTIPOLYGON (((990254.404 178941.971, 990307.... |
5 rows × 114 columns
As you can see, joining based on attributes can be a more straightforward process than the various operations we had to conduct for the spatial join. Now we can compare these results against our previous spatial join results. At a high level, we can see (in the next cell) that the dataframes are not the same length, meaning that at some point, certain features are dropped (or not) in different ways between the different datasets. What do you think those points of difference are?
bldgs_w_lot_attrib.shape[0] == bldgs_w_lot_gdf.shape[0]FalseThey don’t match! How close are they?
print(
f"There are {bldgs_w_lot_attrib.shape[0]} features in the attribute join dataset\nand {bldgs_w_lot_gdf.shape[0]} features in the spatial join dataset"
)There are 14318 features in the attribute join dataset
and 14315 features in the spatial join datasetNot bad- but there are three buildings that our spatial join did not pick up that our attribute join did. Let’s investigate.
Let’s compare the two datasets. Below we’ll plot the longer, more complete list of buildings generated through the attribute join vs. the buildings that do not match between the two. We will use the selection logic in square brackets to perform this selection.
We are selecting from the dataset using the conditions in the square brackets. The ~ operator means not- so we are selecting the reverse of the following statement: bldgs_w_lot_attrib.globalid.isin(bldgs_w_lot_gdf.globalid). This statement looks for cases where the global building id from the attribute join bldgs_w_lot_attrib dataset is in the list of the spatial join dataset’s (bldgs_w_lot_gdf) global ids. Because we start this filter off with the ~, we are asking for cases where IDs are in the attribute join dataset, but not the spatial join dataset.
Filter statements like this can be written in a number of different ways, so be sure to mind each part of the statement as you construct your filter.
# find the globalid of the buildings in bldgs_w_lot_attrib that are not in bldgs_w_lot_gdf
ax = bldgs_w_lot_attrib.plot()
bldgs_w_lot_attrib[~bldgs_w_lot_attrib.globalid.isin(bldgs_w_lot_gdf.globalid)].plot(
ax=ax, color="red"
)<Axes: >
Now let’s look at the inverse and create a new dataframe which includes only the three missing buildings. We’ll use a similar selection logic as before. We’ll then confirm that there are three missing buildings in our dataframe.
missing_buildings = bldgs_w_lot_attrib[
~bldgs_w_lot_attrib.globalid.isin(bldgs_w_lot_gdf.globalid)
].copy()missing_buildings.shape[0]3To be able to visually inspect those missing buildings against our other joined buildings, we’ll have to clean up our joined dataset: because both the lot and the building dataset contained geometry fields, we now have geometry_lot and geometry_bldg. We need to clarify which we want to use. We have a few options:
- we can create a new column named
geometryand set it to the value ofgeometry_bldg, and then set the geodataframe’s geometry column to that usingset_geometry - we can just set the geometry column to be
geometry_bldg.
There is no right or wrong choice here- for the sake of brevity we’ll directly set the geometry column.
bldgs_w_lot_attrib.set_geometry("geometry_bldg", inplace=True)missing_buildings.set_geometry("geometry_bldg", inplace=True)Map the missing buildings
Map the missing buildings and zoom around to find where they are and what kind of spatial relationship(s) they have with the tax lot dataset.
# make a lonboard plot with color based on land use and height based on number of floors
heights_missing = missing_buildings["heightroof"].astype(float).to_numpy()
lots_layer = PolygonLayer.from_geopandas(
cb_307[["geometry", "LandUse"]].to_crs("EPSG:4326"),
get_fill_color=[240, 240, 240, 155],
)
missing_bldgs_layer = PolygonLayer.from_geopandas(
missing_buildings[["geometry_bldg", "LandUse"]].to_crs("EPSG:4326"),
get_fill_color=[255, 0, 0, 155],
extruded=True,
get_elevation=heights_missing,
)
m = Map(
[missing_bldgs_layer, lots_layer],
view_state={
"pitch": 45,
"zoom": 14,
"latitude": 40.6459658,
"longitude": -74.0151512,
},
)
# actually show the map
mSo we can see that there are three cases where buildings are associated with lots, even if their representative point (or entire geometry) fall outside of the actual polygon.
Dissolve
A common geoprocessing operation is to dissolve features based on a shared attribute. This is useful when you want to aggregate data to a higher level of geography, such as aggregating tax lots to blocks or neighborhoods, or based on a shared attribute. This is similar to the groupby() function in pandas, but it also merges the geometries of the features that are being grouped together.
In this case, we will dissolve lots based on the OwnerName field: we will merge all lots that share the same owner into a single polygon. This is useful for understanding the extent of land owned by a particular entity.
You can read more about the dissolve() function in the geopandas documentation.
At the most basic level, you can dissolve all the geometry together into a single feature by not passing any arguments to the dissolve() function- however, this may not be very useful on its own. You can pass the by=... argument to specify which attribute to dissolve by (very similar to the groupby() function in pandas).
You can also specify how you want to treat other attributes in the dataset using the aggfunc=... argument. By default, this is set to first, which means that for each group of features being dissolved, the first value of each attribute will be kept. You can also use other aggregation functions such as sum, mean, min, max, etc. You can also pass a dictionary to specify different aggregation functions for different attributes. In the below example, we will pass a dictionary with two entries:
- we want to get a
listof all of the differentLandUsetypes for each owner (what kinds of land do they own?) - we want to get the
sumof theLotAreafield for each owner (how much land do they own in total?)
Finally, we use the as_index=False argument to ensure that the OwnerName field is kept as a column in the output dataframe, rather than being set as the index. We could instead use reset_index() after the dissolve operation to achieve the same effect.
cb_307_by_owner = cb_307.dissolve(
by="OwnerName",
aggfunc={
"LandUse": list,
"LotArea": "sum",
},
as_index=False,
)Let’s take a look at the top ten owners with the greatest total lot area.
cb_307_by_owner.sort_values("LotArea", ascending=False).head(10)| OwnerName | geometry | LandUse | LotArea | |
|---|---|---|---|---|
| 5133 | GREENWOOD CEMETRY | POLYGON ((984765.258 175999.082, 984925.008 17... | [Open Space & Outdoor Recreation] | 20309060 |
| 8473 | NYC DEPARTMENT OF SMALL BUSINESS SERVICES | MULTIPOLYGON (((977030.251 172629.699, 976946.... | [Industrial & Manufacturing, Transportation & ... | 14330563 |
| 10900 | UNAVAILABLE OWNER | MULTIPOLYGON (((981243.984 170905.64, 981282.8... | [Multi-Family Elevator Buildings, Multi-Family... | 2145841 |
| 8471 | NYC DEPARTMENT OF PARKS AND RECREATION | MULTIPOLYGON (((978465.658 171814.4, 978466.30... | [Open Space & Outdoor Recreation, Open Space &... | 1779509 |
| 2140 | ASTORIA GENERATING COMPANY ACQUISITIONS, L.L.C. | MULTIPOLYGON (((978444.216 175678.927, 978168.... | [Transportation & Utility, Transportation & Ut... | 1493713 |
| 1 | 1-10 BUSH TERMINAL OWNER LP | POLYGON ((982202.987 178074.791, 982200.638 17... | [Commercial & Office Buildings, Industrial & M... | 722097 |
| 8468 | NYC DEPARTMENT OF EDUCATION | MULTIPOLYGON (((978862.322 173019.035, 978673.... | [Public Facilities & Institutions, Public Faci... | 717864 |
| 10051 | SIP HOLDINGS VENTURE, LLC | POLYGON ((984386.571 181329.041, 984380.016 18... | [Commercial & Office Buildings, Industrial & M... | 528901 |
| 2141 | ASTORIA GENERATING COMPANY, L.P. | POLYGON ((983947.513 180523.148, 983958.019 18... | [Transportation & Utility] | 515406 |
| 214 | 19-20 BUSH TERMINAL OWNER LP | POLYGON ((981122.148 177799.108, 980997.043 17... | [Industrial & Manufacturing, Parking Facilitie... | 507505 |
And now let’s map the results using the OwnerName field to color the dissolved polygons.
fig, ax = plt.subplots()
cb_307.plot(color="#cecece", ax=ax, alpha=0.5)
cb_307_by_owner.sort_values("LotArea", ascending=False).head(10).plot(
column="OwnerName", legend=True, ax=ax
)
# get legend item
leg = ax.get_legend()
leg.set_bbox_to_anchor((0.5, 0.0, 0.5, 0.2))
ax.set_title("Top 10 Owners by Lot Area")Text(0.5, 1.0, 'Top 10 Owners by Lot Area')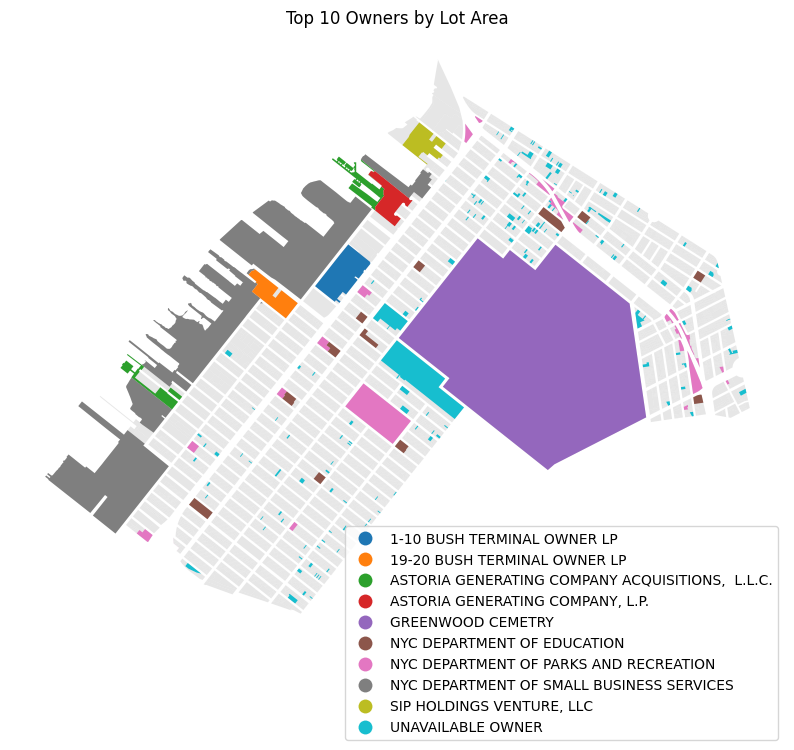
Take a look at the results- what do you notice? It’s clear from the above that the results are limited by the availability of complete data.
Intersect / Difference
Next we’ll perform additional geometric operations to identify the portions of tax lots that are not covered by buildings. This workflow demonstrates how to create a new dataset based on existing inputs.
To begin, we’ll choose a random block within CB 307.
sample_block = cb_307.Block.sample(1).values[0]Now we’ll select the blocks and building footprints that match the randomly selected block, and will create new dataframes for each.
sample_block_lots = cb_307[cb_307.Block.eq(sample_block)].copy()
sample_block_bldgs = cb_307_bldgs[
cb_307_bldgs.mpluto_bbl.isin(sample_block_lots.BBL.unique())
].copy()sample_block_bldgs.set_geometry("geometry", inplace=True)We can plot those to visually inspect the sampled block, lots, and building footprints.
ax = sample_block_lots.boundary.plot(color="black", linewidth=0.5)
sample_block_bldgs.plot(ax=ax, color="red")
ax.set_title(f"Block {sample_block}")Text(0.5, 1.0, 'Block 5256')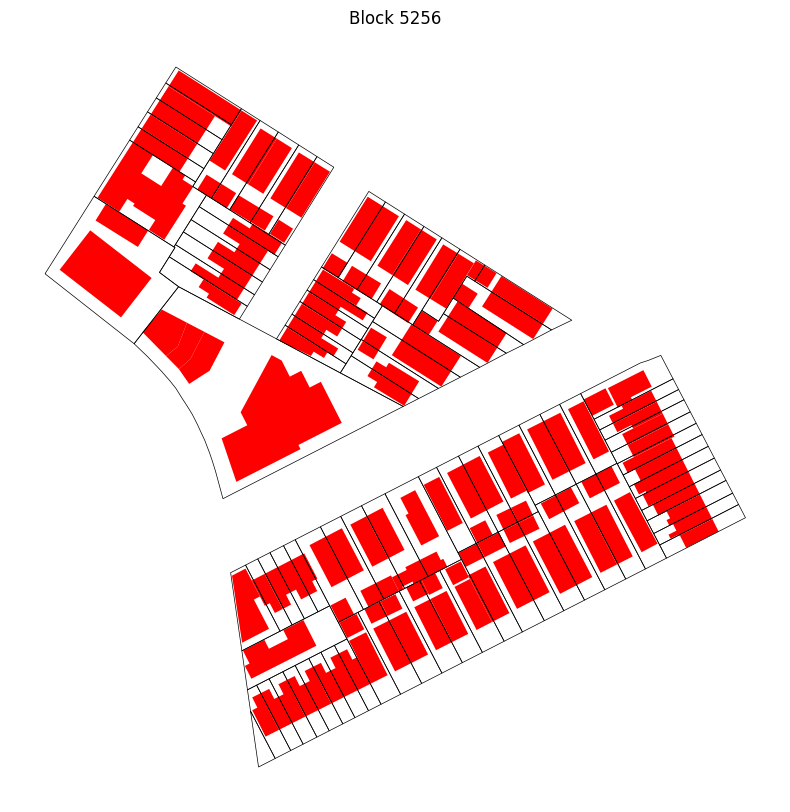
Next we can identify the portions of the block that are not buildings by calculating the difference between the lots and the buildings. We will use the unary_union property of the buildings dataframe, which represents a union of all geometries in the dataframe. It is essentially a shortcut to a dissolve of all geometries in a dataframe.
With these chained commands, we will return the area of each tax lot that is not a building.
sample_block_non_bldg = sample_block_lots.difference(sample_block_bldgs.unary_union)/var/folders/g5/b592wl6x12s0tx4jfw9f7_j40000gn/T/ipykernel_27210/3284385118.py:1: DeprecationWarning: The 'unary_union' attribute is deprecated, use the 'union_all()' method instead.
sample_block_non_bldg = sample_block_lots.difference(sample_block_bldgs.unary_union)We can plot the results to confirm that each lot still exists as its own feature (blue with black outlines) and are separate from the orange building polygons. Note that in some cases, lots may be split into two distinct areas, making them MultiPolygons.
ax = sample_block_non_bldg.boundary.plot(color="black", linewidth=0.5)
sample_block_non_bldg.plot(ax=ax)
sample_block_bldgs.plot(ax=ax, color="orange")<Axes: >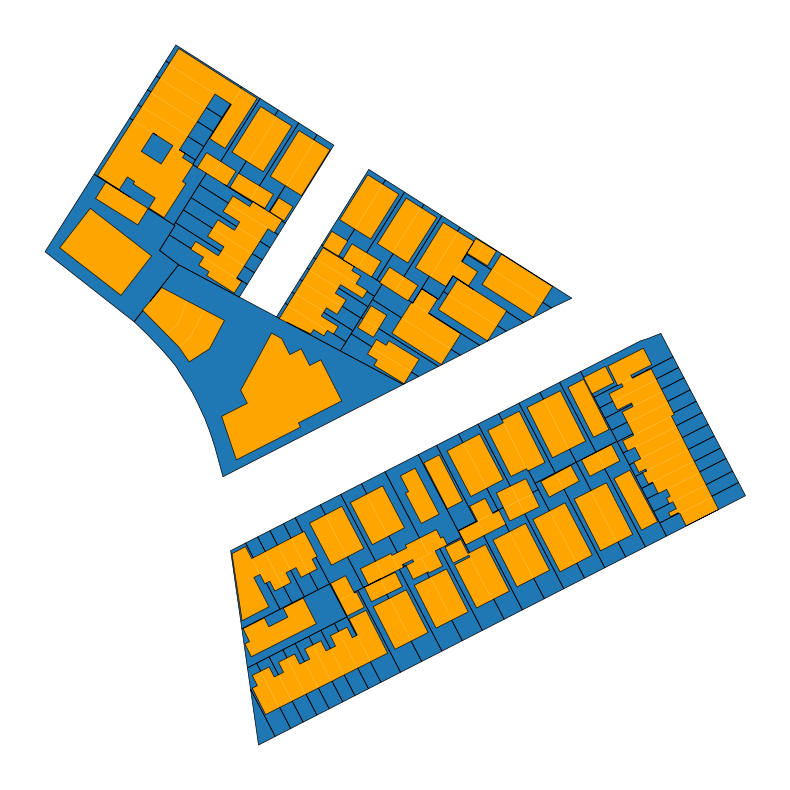
We could use this new dataset to calculate the lot coverage of each lot, which could be useful in a soft site analysis (continued below). Next we will explore another means of calculating lot coverage by unioning features instead of taking the intersection.
Union
We’ll continue using the sample block we identified above. We’ll start by calculating the lot area of each lot in our sample.
sample_block_lots["lot_area"] = sample_block_lots.areaNow we’ll perform a union between the lots and the building footprints. A union, like the difference performed above, is a kind of overlay method that we can apply between multiple dataframes. (For more information on other overlay methods, check out the documentation). The union operation retains all geometry of the input layers, as well as the attributes of each based on the overlap.

Source: QGIS Documentation via Geopandas docs
A union would take the following input:

and produce the following output:

lots_bldgs_union = gpd.overlay(sample_block_lots, sample_block_bldgs, how="union")A union will produce features that have geometry entries (based on the union operation), as well as attributes from both input datasets so long as there is coverage of that dataset. In our example, there will be full attributes of both datasets for the portion of the lots that are buildings, but the other portions of lots will not have attributes from the buildings dataset.
lots_bldgs_union.head()| Borough | Block | Lot | CD | BCT2020 | BCTCB2020 | CT2010 | CB2010 | SchoolDist | Council | ... | lststatype | feat_code | groundelev | geomsource | bin | lstmoddate | doitt_id | shape_len | rep_pt | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BK | 5256.0 | 68.0 | 307.0 | 3017100 | 30171003003 | 171 | 3003 | 15 | 39.0 | ... | Constructed | 5110 | 105 | Photogramm | 3357261 | 2017-08-17 | 873930 | 0.0 | POINT (990962.149 177965.505) | POLYGON ((990973.918 177961.4, 990957.153 1779... |
| 1 | BK | 5256.0 | 68.0 | 307.0 | 3017100 | 30171003003 | 171 | 3003 | 15 | 39.0 | ... | Constructed | 2100 | 104 | Photogramm | 3121828 | 2017-08-22 | 500728 | 0.0 | POINT (990975.429 177937.992) | POLYGON ((991000.756 177909.949, 990983.069 17... |
| 2 | BK | 5256.0 | 69.0 | 307.0 | 3017100 | 30171003003 | 171 | 3003 | 15 | 39.0 | ... | Constructed | 5110 | 102 | Photogramm | 3357262 | 2017-08-17 | 965491 | 0.0 | POINT (990935.627 177950.755) | POLYGON ((990938.466 177962.848, 990940.67 177... |
| 3 | BK | 5256.0 | 69.0 | 307.0 | 3017100 | 30171003003 | 171 | 3003 | 15 | 39.0 | ... | Constructed | 2100 | 103 | Photogramm | 3121829 | 2017-08-22 | 771343 | 0.0 | POINT (990956.069 177910.991) | POLYGON ((990947.137 177905.449, 990941.557 17... |
| 4 | BK | 5256.0 | 69.0 | 307.0 | 3017100 | 30171003003 | 171 | 3003 | 15 | 39.0 | ... | Constructed | 5110 | 103 | Photogramm | 3357263 | 2017-08-17 | 869641 | 0.0 | POINT (990925.324 177968.104) | POLYGON ((990938.084 177963.591, 990938.466 17... |
5 rows × 114 columns
We can illustrate that point by mapping the output layer. In the below example, we filter for cases where the globalid (which is associated with the buildings dataset) is null (.isna()) in grey. Cases where the globalid is not null are red.
ax = lots_bldgs_union[lots_bldgs_union.globalid.isna()].plot(color="#cecece")
lots_bldgs_union[lots_bldgs_union.globalid.notna()].plot(ax=ax, color="red")<Axes: >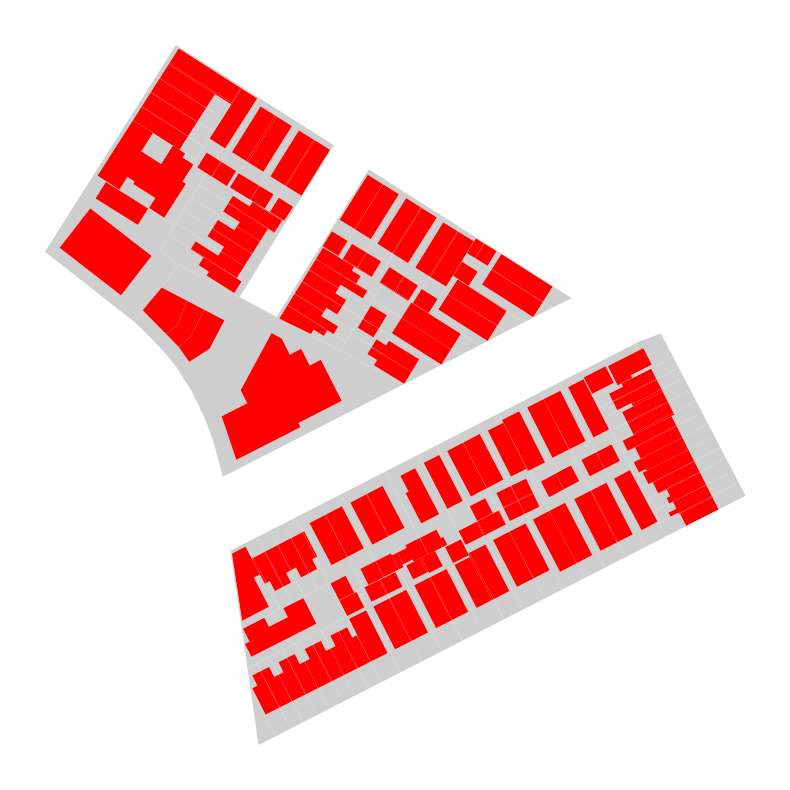
We can also plot based on a shared attribute to demonstrate that both portions of the lots (building and non-building) are part of the same lot. Plotting the boundary separately confirms that each segment of the building/lot combination is in fact a separate feature.
ax = lots_bldgs_union[lots_bldgs_union.globalid.isna()].plot("Lot")
lots_bldgs_union[lots_bldgs_union.globalid.notna()].plot("Lot", ax=ax)
lots_bldgs_union.boundary.plot(color="black", ax=ax, linewidth=0.5)<Axes: >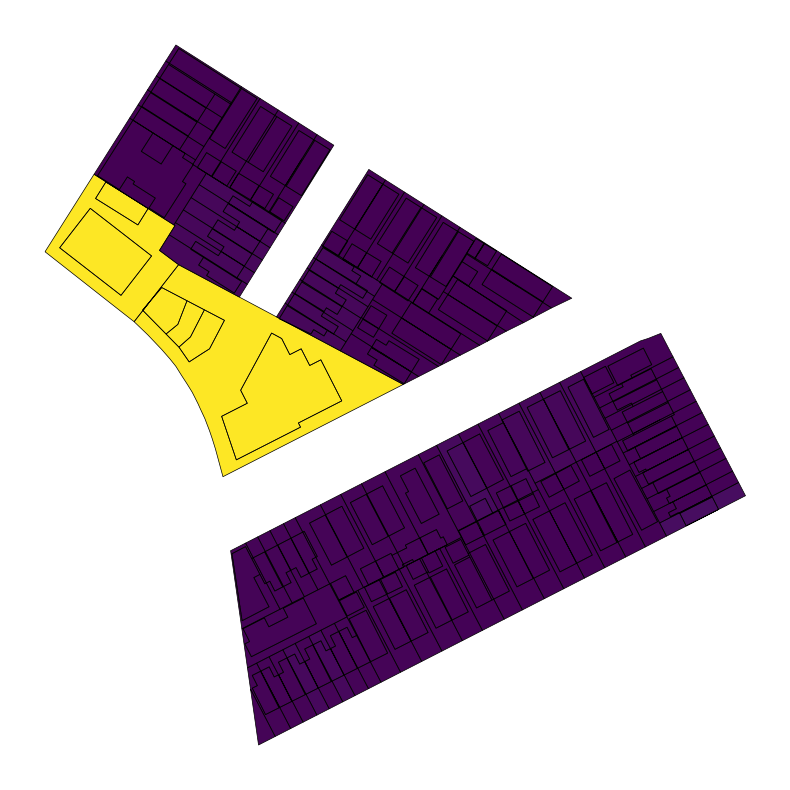
Finally, we can create a new attribute field that represents the percent of the lot that is covered by a building as discussed above. The below operation uses a lambda function, which is a way to iterate through a dataframe and perform a calculation on each row (or column, based on the axis=... argument). The function can be understood as follows:
lambda x: ... axis=1for each row (x, based on the1axis value), perform the following operation((x.geometry.area / x.lot_area)*100...): take the geometry of each piece of the unioned dataframe, calculate the area, divide it by the lot area (which we calculated above, pre-union), and multiply by 100 to get a percentageif type(x.globalid) == str else -1: only do this for the input features that are pieces of buildings (e.g. they have aglobalid), otherwise return a placeholder value of-1. This number is negative on purpose so it is easy to filter out, but you could also useNoneorNaNif you prefer.
As you can see, we can perform a multi-step operation using a lambda function. For more complex operations, it makes sense to write standalone functions for legibility- we’ll demonstrate that in the following section. There is no hard rule for legibility vs. brevity (i.e. lambda vs standalone functions), so use your best judgement. What’s important is that you or your user understand what the code is doing.
lots_bldgs_union["pct_bldg_lot_coverage"] = lots_bldgs_union.apply(
lambda x: ((x.geometry.area / x.lot_area) * 100 if type(x.globalid) == str else -1),
axis=1,
)Now let’s plot and see the percentage of each lot that is covered by buildings. This could be expressed in a number of different ways (e.g. at the lot level) but we can get a sense of the utility of the union operation.
lots_bldgs_union.plot("pct_bldg_lot_coverage", legend=True)<Axes: >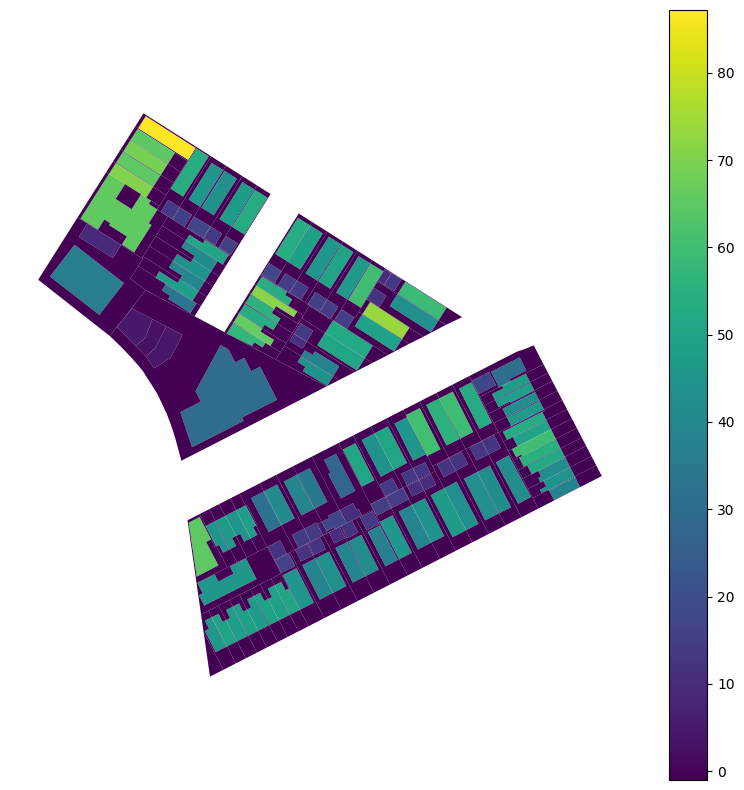
Creating new attributes
In this example, we’ll develop a function that indicates whether a site is a “soft site” or not. A “soft site” is a site that meets certain criteria for redevelopment. The factors below represent just a few of the considerations that are often taken to determine whether a site may be a good candidate for redevelopment, but this is a simplistic example case to illustrate a point rather than a firm ruleset.
Because we are considering a few different factors, we will write a new function vs. chaining criteria together in a lambda function (although you could use the same kind of syntax above to perform the same work).
There are several important components to consider.
def [function_name]([input_args...]):
The instantiation of the function is important. We are defining (def) a new function, giving it a name (in this case, is_soft_site), and indicating that there are two possible input arguments: r, which is a common shorthand for a row in a dataset, and the optional argument threshold. This is optional and comes with a default value of 0.33, meaning that if a user doesn’t specify a threshold, 0.33 will be used. You could imagine other cases where required or optional arguments might be useful!
if (...): return 1 else: return 0
This is the part of the function that is evaluating properties of our input r based on it’s properties. We can see the evaluation of its BuiltFAR compared to the lot’s ResidFAR (allowed residential FAR) times the threshold set here. We are determining whether the site is built less than or equal to 33% of the allowable residential FAR.
We then evaluate the lot area, existing land use, and whether there is available residential FAR at all to indicate that yes, this is a soft site, or no, it is not. The return statements are what pass that information back to us: if those conditions are met, we get a 1, otherwise a 0.
Functions don’t necessarily have to return anything, but in this case we will be using this logic to create a new field and so want to be sure that something is always returned.
def is_soft_site(r, threshold=0.33):
if (
r.BuiltFAR <= r.ResidFAR * threshold
and r.LotArea > 10000
and r.LandUse != "Open Space & Outdoor Recreation"
and r.ResidFAR > 0
):
return 1
else:
return 0We can invoke the function using the apply() method- here we pass in the function name, and specify that we want to apply the function to each row (axis=1) vs each column (axis=0) of our table.
If we wanted to pass in a threshold value, we could pass in a tuple of arguments: ...apply(is_soft_site, axis=1, args=(0.5,)) which is then passed in as a different threshold. Part of the point of providing these optional attributes is to make it easier for you / your users to make changes quickly- in a more complex example you might also have arguments for your lot area thresholds, the land uses that are off limits, etc.
cb_307["soft_site"] = cb_307.apply(is_soft_site, axis=1)Now let’s check how many soft sites we have in the neighborhood based on the criteria we defined above. Because we use 1/0 values to distinguish soft sites from not, we can use the value_counts() method to get a quick overview of the number of soft sites in the neighborhood.
cb_307["soft_site"].value_counts()soft_site
0 13251
1 33
Name: count, dtype: int64Now let’s create a quick map to see where our soft sites are. What do you notice about the distribution of sites?
ax = cb_307.plot(color="#cecece", alpha=0.5)
cb_307[cb_307.soft_site > 0].plot("soft_site", ax=ax, legend=True, categorical=True)
plt.title("Soft Sites in Community Board 307")Text(0.5, 1.0, 'Soft Sites in Community Board 307')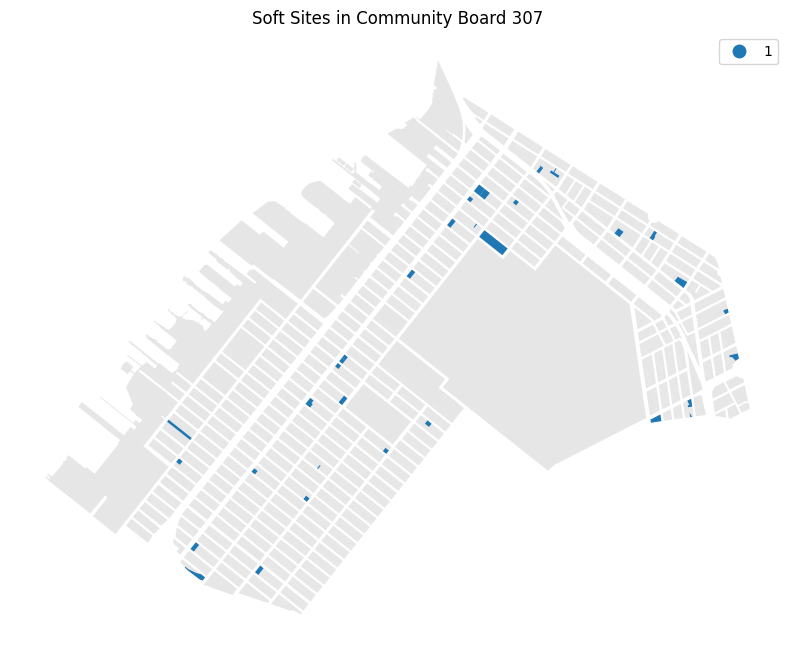
cb_307[cb_307.soft_site.eq(1)][["soft_site", "BuiltFAR", "ResidFAR"]]| soft_site | BuiltFAR | ResidFAR | |
|---|---|---|---|
| 116 | 1 | 0.05 | 1.25 |
| 125 | 1 | 0.69 | 2.43 |
| 529 | 1 | 0.18 | 4.00 |
| 538 | 1 | 0.59 | 3.00 |
| 796 | 1 | 0.41 | 1.35 |
| 1642 | 1 | 0.97 | 6.02 |
| 1656 | 1 | 0.09 | 2.00 |
| 1696 | 1 | 0.00 | 6.02 |
| 1738 | 1 | 0.40 | 2.00 |
| 1905 | 1 | 0.32 | 2.00 |
| 2383 | 1 | 0.54 | 2.00 |
| 2445 | 1 | 0.00 | 2.00 |
| 3370 | 1 | 0.18 | 1.35 |
| 3456 | 1 | 0.00 | 1.35 |
| 4234 | 1 | 0.00 | 2.00 |
| 4592 | 1 | 0.13 | 4.00 |
| 4992 | 1 | 0.00 | 6.02 |
| 5642 | 1 | 0.00 | 2.00 |
| 5740 | 1 | 0.60 | 4.00 |
| 6046 | 1 | 0.59 | 3.00 |
| 6665 | 1 | 0.98 | 4.00 |
| 7199 | 1 | 0.02 | 3.00 |
| 7669 | 1 | 0.00 | 2.43 |
| 8386 | 1 | 0.19 | 4.00 |
| 8514 | 1 | 0.65 | 4.00 |
| 8515 | 1 | 0.22 | 4.00 |
| 8615 | 1 | 0.90 | 3.00 |
| 8986 | 1 | 0.72 | 4.00 |
| 9443 | 1 | 0.38 | 2.00 |
| 9985 | 1 | 0.50 | 3.00 |
| 11044 | 1 | 0.44 | 4.00 |
| 11676 | 1 | 0.54 | 4.00 |
| 12317 | 1 | 0.14 | 1.25 |
# map soft sites
soft_sites = cb_307[cb_307.soft_site.eq(1)].copy().to_crs("EPSG:4326")
soft_sites["ResidFAR"]
lots_layer = PolygonLayer.from_geopandas(
soft_sites[["geometry", "ResidFAR"]],
extruded=True,
get_elevation=soft_sites["ResidFAR"] * 15, # scale elevation for visibility
pickable=True,
)
base_layer = PolygonLayer.from_geopandas(
cb_307[["geometry", "LandUse"]].to_crs("EPSG:4326"),
get_fill_color=[200, 200, 200, 155],
)
m = Map(
[base_layer, lots_layer],
view_state={
"pitch": 45,
"zoom": 14,
"latitude": 40.6459406,
"longitude": -74.0151512,
},
)
m